Imagine a world where data integration is no longer a headache. With AWS Glue, that world is real—offering a fully managed, serverless ETL service that simplifies how you move, transform, and analyze data across your cloud ecosystem.




What Is AWS Glue and Why It’s a Game-Changer

AWS Glue is Amazon Web Services’ fully managed extract, transform, and load (ETL) service designed to make data preparation and movement seamless. It automates the heavy lifting of data integration, allowing developers, data engineers, and analysts to focus on insights rather than infrastructure.
Core Definition and Purpose
AWS Glue is built to handle the complexities of modern data workflows. It discovers, catalogs, transforms, and routes data across various sources and targets—whether they’re in Amazon S3, RDS, Redshift, or external databases. Its serverless architecture means you don’t need to provision or manage servers, reducing operational overhead significantly.
- Automatically discovers data through crawlers
- Creates and maintains a centralized data catalog
- Generates ETL scripts in Python or Scala
Unlike traditional ETL tools that require manual configuration and server maintenance, AWS Glue abstracts away infrastructure concerns. This makes it ideal for organizations scaling their data pipelines without increasing DevOps burden.
How AWS Glue Fits Into the Modern Data Stack
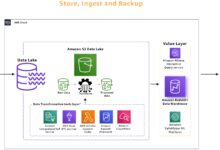
In today’s data-driven landscape, companies collect information from multiple sources—web apps, IoT devices, CRM systems, and more. AWS Glue acts as the connective tissue, enabling these disparate datasets to be unified into a coherent data lake or warehouse.
It integrates natively with other AWS services like Amazon Athena, Redshift, and EMR, forming a powerful ecosystem for analytics. For example, once AWS Glue cleans and structures your data, Amazon Athena can query it directly using standard SQL—no additional processing needed.
“AWS Glue removes the friction from data integration, making it easier than ever to turn raw data into actionable insights.” — AWS Official Documentation
Key Components of AWS Glue Architecture
To truly harness the power of AWS Glue, it’s essential to understand its core architectural components. Each plays a distinct role in the ETL lifecycle, working together to automate and streamline data workflows.
Data Catalog and Crawlers
The AWS Glue Data Catalog is a persistent metadata store that acts as a central repository for table definitions, schema information, and partition details. Think of it as a dynamic, searchable inventory of all your data assets.
Crawlers are the discovery agents of AWS Glue. They scan your data sources—such as S3 buckets, JDBC databases, or DynamoDB tables—and infer schema, data types, and relationships. Once complete, they populate the Data Catalog with updated metadata.
- Crawlers support custom classifiers for non-standard formats
- Can run on a schedule or be triggered by events (e.g., new files in S3)
- Supports schema evolution detection
For instance, if you add a new column to a CSV file uploaded to S3, the next crawler run will detect this change and update the catalog accordingly—ensuring your pipelines remain resilient to schema drift.
Glue ETL Jobs and Scripts
At the heart of AWS Glue are ETL jobs—executable units that perform data transformation logic. You can author these jobs using PySpark (Python) or Scala, and AWS Glue provides a visual editor to simplify development.
When you create a job, AWS Glue automatically generates a script based on your source and target data. You can then customize this script to implement business logic—filtering records, joining datasets, or applying machine learning models.
- Jobs run on a serverless Spark environment
- Support for custom libraries and Python packages
- Integration with AWS IAM for secure access control
One powerful feature is job bookmarks, which track processed data to prevent reprocessing. This is crucial for incremental data loads, ensuring efficiency and cost control.
Glue Workflows and Orchestration
As data pipelines grow in complexity, managing dependencies between jobs becomes critical. AWS Glue Workflows provide a visual way to orchestrate multiple jobs, crawlers, and triggers into a cohesive pipeline.
You can define conditional logic—such as running a data quality check after a transformation job—and set up notifications via Amazon SNS. Workflows also support branching and parallel execution, enabling sophisticated pipeline designs.
- Visual drag-and-drop interface for building workflows
- Support for event-based and time-based triggers
- Integration with AWS Step Functions for advanced orchestration
This level of control ensures that your data pipelines are not only automated but also reliable and auditable.
Setting Up Your First AWS Glue Job: A Step-by-Step Guide
Getting started with AWS Glue might seem daunting, but the process is streamlined and intuitive. Let’s walk through creating your first ETL job—from data discovery to execution.
Step 1: Configure a Data Source with Crawlers
Begin by setting up a crawler to scan your data source. Navigate to the AWS Glue Console, select “Crawlers,” and click “Add crawler.”
Define the data store—say, an S3 bucket containing CSV files—and choose an IAM role with read permissions. Then, specify a schedule (on-demand or periodic) and point the crawler to your data location.
After running, the crawler will create a database and table in the Data Catalog. You can inspect the inferred schema and make adjustments if needed.
- Use custom regex classifiers for log files or semi-structured data
- Apply include/exclude patterns to filter files
- Leverage Lake Formation integration for fine-grained access control
For more details on configuring crawlers, visit the official AWS Glue crawler documentation.
Step 2: Create and Customize an ETL Job
With your data cataloged, go to the Jobs section and click “Create job.” Select your source (the table from the crawler) and target (e.g., another S3 path or Redshift cluster).
AWS Glue will generate a PySpark script. You can edit it directly in the console or download it for local development. Common transformations include:
- Dropping null values
- Renaming columns
- Converting data types
- Joining with reference datasets
For example, you might filter customer records where `age > 18` and convert timestamps to a standardized format. Once satisfied, save and run the job.
Step 3: Monitor and Optimize Job Performance
After execution, monitor your job’s performance using CloudWatch metrics and the AWS Glue console. Key indicators include:
- Execution duration
- Number of records processed
- Memory and executor utilization
If a job runs slowly, consider increasing the number of DPUs (Data Processing Units)—AWS Glue’s compute capacity metric. You can also enable job bookmarks to avoid reprocessing unchanged data.
“Optimizing DPU allocation can reduce job runtime by up to 60% in some cases.” — AWS Performance Best Practices
Advanced AWS Glue Features You Should Know
Beyond basic ETL, AWS Glue offers advanced capabilities that elevate its functionality for enterprise-grade data engineering.
Glue Studio: Visual ETL Development
AWS Glue Studio provides a no-code/low-code interface for building ETL jobs. It features a drag-and-drop canvas where you can connect sources, transformations, and sinks visually.
This is especially useful for teams with mixed technical expertise—analysts can prototype pipelines without writing code, while engineers can export and refine the generated scripts.
- Real-time data preview during design
- Pre-built transformation templates (e.g., filter, aggregate, pivot)
- Support for streaming ETL with Apache Kafka and Kinesis
Glue Studio lowers the barrier to entry for data integration, accelerating time-to-insight across departments.
Streaming ETL with AWS Glue
While traditionally used for batch processing, AWS Glue now supports streaming ETL. This allows you to process data in real-time from sources like Amazon Kinesis or MSK (Managed Streaming for Kafka).
Streaming jobs continuously ingest and transform data, enabling use cases such as:
- Real-time fraud detection
- Live dashboard updates
- IoT sensor data aggregation
Streaming ETL jobs are built using the same PySpark framework, ensuring consistency across batch and real-time workflows.
Machine Learning Transforms: FindMatches
AWS Glue includes built-in machine learning capabilities to handle complex data quality tasks. The most notable is FindMatches, which deduplicates and links similar records—like identifying that “John Doe” and “J. Doe” refer to the same person.
You train a FindMatches transform using labeled data, and AWS Glue builds a custom ML model. Once deployed, it can be used within ETL jobs to clean and standardize datasets.
- Reduces manual data matching efforts by up to 90%
- Improves data accuracy for customer 360 views
- Supports iterative model improvement
This feature is a game-changer for CRM integration, M&A data consolidation, and regulatory compliance.
Integrating AWS Glue with Other AWS Services
AWS Glue doesn’t operate in isolation—it’s designed to work seamlessly within the broader AWS ecosystem.
Integration with Amazon S3 and Data Lakes
Amazon S3 is the de facto storage layer for data lakes, and AWS Glue is the engine that powers them. Glue crawlers catalog S3 data, while ETL jobs transform it into optimized formats like Parquet or ORC for faster querying.
When combined with AWS Lake Formation, you gain centralized governance—defining who can access what data, with audit trails and encryption policies.
- Automate partitioning for large datasets
- Enforce GDPR/CCPA compliance through tagging
- Enable zero-copy data sharing across accounts
For best practices on S3 integration, see AWS’s guide on S3 data organization.
Connecting to Amazon Redshift and RDS
AWS Glue can extract data from relational databases like RDS (MySQL, PostgreSQL) and load it into Redshift for analytics. It supports full and incremental loads, minimizing impact on source systems.
Using JDBC connections, Glue reads data efficiently and can push down predicates to reduce network transfer. For large tables, it automatically splits reads across multiple workers for parallel processing.
- Use Glue to migrate on-prem databases to AWS
- Replicate transactional data for BI reporting
- Synchronize data across hybrid environments
This makes AWS Glue a cornerstone of modern data warehouse architectures.
Security and Compliance with IAM and KMS
Security is paramount in data integration. AWS Glue integrates tightly with IAM to enforce least-privilege access and with KMS for encryption at rest.
You can encrypt job scripts, temporary data, and output using customer-managed keys. Additionally, Glue supports VPC endpoints, allowing private connectivity to resources without exposing them to the public internet.
- Enable CloudTrail logging for audit trails
- Use Lake Formation for row- and column-level security
- Apply SCPs (Service Control Policies) in multi-account setups
“Security is not an afterthought in AWS Glue—it’s built into every layer of the service.” — AWS Security Whitepaper
Cost Optimization Strategies for AWS Glue
While AWS Glue is serverless and scales automatically, costs can escalate if not managed properly. Understanding pricing levers is key to maintaining efficiency.
Understanding DPU and Compute Costs
AWS Glue charges based on DPU-hours—the amount of processing power used. One DPU provides 4 vCPUs and 16 GB of memory, suitable for moderate workloads.
Jobs are billed per second (minimum 10 minutes), so optimizing job duration directly impacts cost. Strategies include:
- Right-sizing DPUs (start with 2–10 and scale as needed)
- Using job bookmarks to avoid reprocessing
- Partitioning input data to reduce scan volume
For example, a job that runs for 15 minutes on 5 DPUs costs 1.25 DPU-hours. Reducing runtime to 8 minutes cuts cost by nearly half.
Minimizing Crawler and Catalog Costs
Crawlers are relatively low-cost, but frequent or large-scale runs can add up. To optimize:
- Schedule crawlers only when necessary (e.g., after data uploads)
- Use S3 event notifications to trigger crawlers instead of polling
- Limit scope with include/exclude patterns
The Data Catalog itself is inexpensive, but excessive table creation or versioning can complicate governance. Apply lifecycle policies and naming conventions to maintain order.
Leveraging Spot Instances and Auto-Scaling
For non-critical jobs, AWS Glue supports Spot Instances—reducing compute costs by up to 70%. While there’s a risk of interruption, Glue handles recovery gracefully.
You can also enable auto-scaling based on workload, ensuring you only pay for what you use. Combine this with CloudWatch alarms to detect underutilized jobs and adjust configurations.
- Use Spot for development and testing environments
- Reserve DPUs for production workloads
- Monitor cost trends with AWS Cost Explorer
For detailed pricing, refer to AWS Glue pricing page.
Common Challenges and Best Practices in AWS Glue
Even with its automation, AWS Glue presents challenges that require thoughtful design and management.
Handling Schema Evolution and Data Drift
Data sources often change—new columns, renamed fields, or altered formats. AWS Glue crawlers detect these changes, but unmanaged schema evolution can break ETL jobs.
Best practices include:
- Enable schema versioning in the Data Catalog
- Use dynamic frames in PySpark to handle missing fields
- Implement pre-job validation scripts
For example, using from_catalog with schema_change_policy allows jobs to adapt to minor schema shifts without failure.
Debugging and Monitoring Glue Jobs
When jobs fail, diagnosing the issue quickly is crucial. AWS Glue integrates with CloudWatch Logs and CloudTrail for detailed diagnostics.
Common issues include:
- Permission errors (IAM roles)
- Memory overflow (increase DPUs)
- Serialization errors (check data format)
Enable continuous logging and set up SNS alerts for job failures. Use the Glue console’s job run history to compare successful and failed executions.
Performance Tuning and Parallelism
To maximize throughput, optimize job parallelism and data partitioning. Large datasets should be split into smaller files to enable parallel processing.
- Use
repartition()orcoalesce()in Spark - Avoid small files (under 128 MB) in S3
- Enable compression (Snappy, GZIP) for output
Additionally, consider using Glue 3.0 with Spark 3.1+ for improved performance and new APIs.
Future of AWS Glue: Trends and Roadmap
AWS Glue continues to evolve, reflecting broader trends in data engineering and cloud computing.
Increased AI and ML Integration
Expect deeper integration with Amazon SageMaker and Bedrock, enabling AI-powered data transformation. Future versions may include auto-generated data quality rules or anomaly detection in pipelines.
For example, Glue could automatically suggest schema mappings or detect outliers during ingestion—reducing manual oversight.
Enhanced Streaming and Real-Time Capabilities
As real-time analytics demand grows, AWS Glue will likely expand its streaming features—supporting more sources, lower latency, and stateful processing.
Potential enhancements include native support for change data capture (CDC) and integration with AWS AppSync for GraphQL-based data routing.
Improved Developer Experience and CI/CD Support
Modern data teams require DevOps practices. AWS Glue is moving toward better CI/CD integration—supporting Git repositories, automated testing, and infrastructure-as-code (IaC) via CloudFormation and Terraform.
Future updates may include built-in debugging tools, local development containers, and enhanced IDE support.
What is AWS Glue used for?
AWS Glue is used for automating data integration tasks such as discovering, cataloging, cleaning, transforming, and loading data from various sources into data lakes, warehouses, or analytics platforms. It’s ideal for ETL/ELT workflows in the cloud.
Is AWS Glue serverless?
Yes, AWS Glue is a fully serverless service. You don’t need to manage servers or clusters—AWS handles provisioning, scaling, and maintenance automatically based on job requirements.
How much does AWS Glue cost?
AWS Glue pricing is based on DPU-hours for ETL jobs, crawler runtime, and data catalog usage. There’s no upfront cost, and you pay only for what you use. Detailed pricing is available on the AWS website.
Can AWS Glue handle real-time data?
Yes, AWS Glue supports streaming ETL for real-time data processing from sources like Amazon Kinesis and MSK. This allows continuous ingestion and transformation of data streams.
How does AWS Glue compare to traditional ETL tools?
Unlike traditional ETL tools that require infrastructure management, AWS Glue is serverless, automated, and tightly integrated with AWS services. It reduces setup time, scales elastically, and includes built-in ML capabilities for data quality.
From automated data discovery to intelligent transformation and seamless cloud integration, AWS Glue stands as a powerful solution for modern data challenges. By leveraging its serverless architecture, rich feature set, and deep AWS ecosystem integration, organizations can build scalable, efficient, and future-ready data pipelines. Whether you’re just starting out or optimizing enterprise workflows, AWS Glue offers the tools and flexibility to turn data into a strategic asset.
Further Reading: